About me

I can design robust and effecient ETL pipeline for data deliveravbles .
I can help you with data analysis things including statistics and data visualization.
Using Hadoop, Kafka, Hive for Big Data processing
DataStream Optimization"
I developed and optimized a variety of data-driven solutions across multiple platforms, significantly enhancing operational efficiency and accuracy. My contributions included architecting scalable data pipelines with Apache Kafka and Hadoop, reducing processing times by 35%, and creating a centralized data warehouse on Amazon Redshift that improved data retrieval for business reporting. I collaborated on deploying machine learning models using Apache Spark, improving credit risk predictions by 20%. Additionally, I automated ETL processes with Apache Airflow, enhanced data security with AWS KMS and IAM, and led a cost-effective migration to AWS, all while maintaining stringent data governance standards.
Visit Website
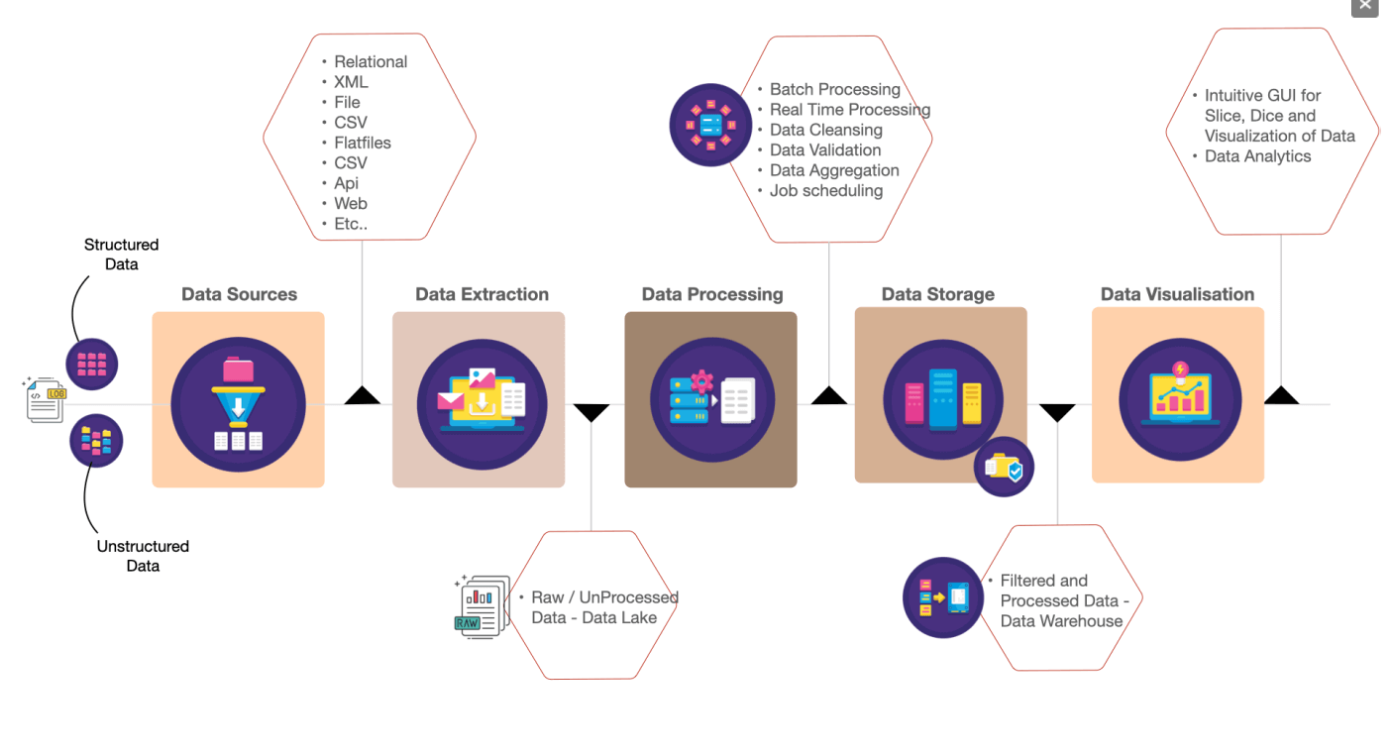
Data Dynamics:Integrated Aviation Analytics Platform
In my role as a Data Engineer, I developed and managed a robust data pipeline utilizing Google Cloud Dataflow and BigQuery, achieving a 30% boost in operational efficiency for flight operations analysis. I designed and implemented a data lake in Google Cloud Storage for versatile handling of unstructured data. Real-time data ingestion was enhanced using Google Cloud Pub/Sub, significantly reducing latency. I automated data quality checks with dbt, improving accuracy by 20%. Collaboratively, I improved query performance and data retrieval times by 40% through optimized data marts in BigQuery. My efforts in data security and cost optimization further solidified system reliability and efficiency.
Visit WebsiteData Migration and Transformation
As a Data Engineer, I have significantly enhanced data processing and storage capabilities by engineering and optimizing data pipelines with Apache NiFi and Hive, achieving a 40% increase in efficiency. I've developed and maintained a data warehouse to streamline data retrieval for analytics teams and implemented machine learning models via Apache Spark, increasing marketing effectiveness by 15%. Additionally, I automated ETL processes using Apache Oozie, reducing manual data handling by 35%, and led a cost-effective migration to AWS Cloud, which cut infrastructure costs by 30%. My work in optimizing database performance and predictive modeling has substantially improved business decision-making and operational efficiency..
Visit Website
With five years of experience as a Data Engineer, I specialize in designing, developing, and optimizing scalable data pipelines and architectures. I am proficient with technologies like Apache Spark, Hadoop, and various cloud platforms (AWS, GCP, Azure), adept at managing large datasets efficiently. My skills extend to programming in Python, Java, and SQL, enabling me to implement robust data solutions that enhance business intelligence and analytics. I am experienced in ETL processes, data warehousing, and leveraging big data technologies. My work consistently supports data-driven decision-making, ensuring data integrity and performance in dynamic environments.
Read moreFor collaboration, contact me on my mail.